差異估算值有何差異
差異差異(DiD)是一種工具,可以比較治療結果與治療前後的差異來估計治療效果,對照組。通常,我們有興趣估算治療$ D_i $(例如,工會狀況,藥物等)對結局$ Y_i $(例如,工資,健康等)的影響,如in $$ Y_ {it} = \ alpha_i + \ lambda_t + \ rho D_ {it} + X'_ {it} \ beta + \ epsilon_ {it} $$,其中$ \ alpha_i $是固定的個體效應(個體特徵不會隨時間變化), $ \ lambda_t $是時間固定的影響,$ X_ {it} $是隨時間變化的協變量,例如個體的年齡,而$ \ epsilon_ {it} $是錯誤項。個人和時間分別由$ i $和$ t $索引。如果固定效應和$ D_ {it} $之間存在相關性,則在不控制固定效應的情況下,通過OLS估算此回歸將存在偏差。這是典型的遺漏的變量偏差。
要了解某項治療的效果,我們想知道一個人在接受治療的世界中與接受治療的人之間的區別她沒有。當然,實際上只有其中之一是可觀察到的。因此,我們尋找預後趨勢相同的患者。假設我們有兩個週期$ t = 1、2 $和兩個組$ s = A,B $。然後,假設在不進行治療的情況下,治療組和對照組的趨勢將與以前一樣繼續,我們可以將治療效果估計為$$ rho =(E [Y_ {ist} | s = A,t = 2]-E [Y_ {ist} | s = A,t = 1])-(E [Y_ {ist} | s = B,t = 2]-E [Y_ {ist} | s = B,t = 1])$$
從圖形上看,這看起來像這樣: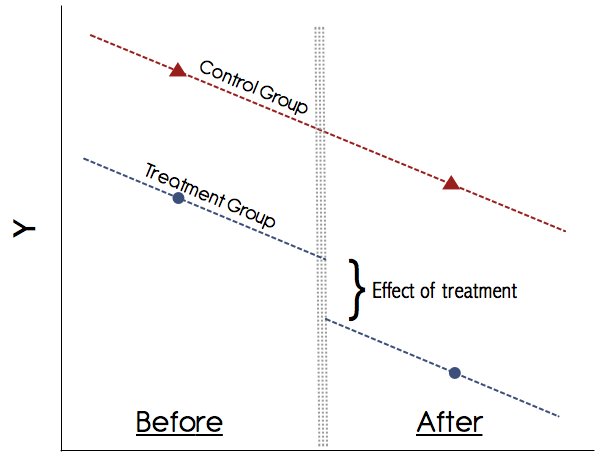
您可以簡單地手動計算這些均值,即獲得兩個時期中$ A $組的平均結果並取它們的差。然後獲得兩個時期中$ B $組的平均結果並取它們的差。然後採取差異,這就是治療效果。但是,在回歸框架中執行此操作更為方便,因為這允許您
- 控制協變量
- 以獲得治療效果的標準誤,以查看是否意義重大
為此,您可以採用兩種等效的策略之一。如果一個人在$ A $組中,則生成一個等於1的控制組虛擬$ \ text {treat} _i $,否則,則生成0,如果一個$則生成一個時間啞元$ \ text {time} _t $ t = 2 $,否則為0,然後回歸$$ Y_ {it} = \ beta_1 + \ beta_2(\ text {treat} _i)+ \ beta_3(\ text {time} _t)+ \ rho(\ text {treat } _i \ cdot \ text {time} _t)+ \ epsilon_ {it} $$
或者您只是生成一個虛擬$ T_ {it} $,如果一個人在治療組中,則等於1,並且該時間段是後處理時間段,否則為零。然後您將回歸$$ Y_ {it} = \ beta_1 \ gamma_s + \ beta_2 \ lambda_t + \ rho T_ {it} + \ epsilon_ {it} $$
其中$ \ gamma_s $再次是對照組的虛擬對象和$ \ lambda_t $是時間虛擬變量。對於兩個時期和兩個組,這兩個回歸為您提供相同的結果。第二個方程式比較籠統,因為它很容易擴展到多個組和多個時間段。在這兩種情況下,您都可以通過這種方式估算差異參數的差異,以便可以包括控制變量(我從上述等式中省略了這些變量,以免使它們混亂,但您可以簡單地包括它們)並獲得標準誤差
為什麼差異估算器中的差異有用?
如前所述,DiD是一種利用非實驗數據估算治療效果的方法。這是最有用的功能。 DiD也是固定效果估算的一種形式。固定效果模型假定$ E(Y_ {0it} | i,t)= \ alpha_i + \ lambda_t $,而DiD做出了類似的假設,但在組級別,$ E(Y_ {0it} | s,t)= \ gamma_s + \ lambda_t $。因此,此處結果的期望值是組和時間效應的總和。那有什麼區別呢?對於DiD,只要重複的橫截面是從相同的合計單位$ s $中繪製出來的,則不一定需要面板數據。與需要面板數據的標準固定效果模型相比,這使DiD適用於更廣泛的數據。
我們可以相信差異的差異嗎?
最重要的假設DiD中的平行趨勢假設(請參見上圖)。永遠不要相信沒有以圖形方式顯示這些趨勢的研究! 1990年代的論文可能已經擺脫了這一點,但是如今,我們對DiD的理解要好得多。如果沒有令人信服的圖表顯示治療組和對照組的治療前結果有平行趨勢,請保持謹慎。如果平行趨勢假設成立,並且我們可以可靠地排除可能混淆治療的任何其他時變變化,則DiD是一種值得信賴的方法。
當涉及標準錯誤的處理。使用多年的數據,您需要調整標準誤差以進行自相關。在過去,這一點一直被忽略,但是從 Bertrand等人開始。 (2004)“我們應該信任差異估計中的多少?”我們知道這是一個問題。在本文中,它們為處理自相關提供了幾種補救措施。最簡單的方法是在單個面板標識符上進行聚類,從而允許各個時間序列之間的殘差任意相關。這可以同時校正自相關和異方差。
有關更多參考,請參閱 Waldinger和 Pischke的這些講義。