I將描述最通用的解決方案。解決這種普遍性的問題使我們可以實現非常緊湊的軟件實現:僅需兩行 R 代碼即可。
選擇向量 $ X $ span>,其長度與 $ Y $ span>,根據您喜歡的任何分佈。讓 $ Y ^ \ perp $ span>是 $ X $ span>對 $ Y $ span>:這會從 $ Y $ span>組件span class =“ math-container”> $ X $ span>。通過將 $ Y $ span>的適當倍數加回 $ Y ^ \ perp $ span>,我們可以生成一個向量具有 $ \ rho $ span>與 $ Y $ span>的任何期望的相關性。最多可以有一個任意的加法常數和正乘法常數(您可以通過任何方式自由選擇),解決方案是
$$ X_ {Y; \ rho} = \ rho \,\ operatorname {SD}(Y ^ \ perp)Y + \ sqrt {1- \ rho ^ 2} \,\ operatorname {SD}(Y)Y ^ \ perp。$$ span>
(“ $ \操作員名稱{SD} $ span>”表示與標準偏差成比例的任何計算。)
這裡是有效的 R 代碼。如果您不提供 $ X $ span>,則代碼將從多元標準正態分佈中提取其值。
互補<-函數(y,rho,x){
if(missing(x))x <- rnorm(length(y))#可選:如果未指定`x',則提供默認值
y.perp <-殘差(lm(x〜y))
rho * sd(y.perp)* y + y.perp * sd(y)* sqrt(1-rho ^ 2)
}
為了說明,我生成了一個隨機的 $ Y $ span>和 $ 50 $ span>組件,並生成了 $ X_ {Y; \ rho} $ span>與此 $ Y $ span>具有各種指定的相關性。它們都是使用相同的起始向量 $ X =(1,2,\ ldots,50)$ span>創建的。這是他們的散點圖。每個面板底部的“地毯”顯示常見的 $ Y $ span>向量。
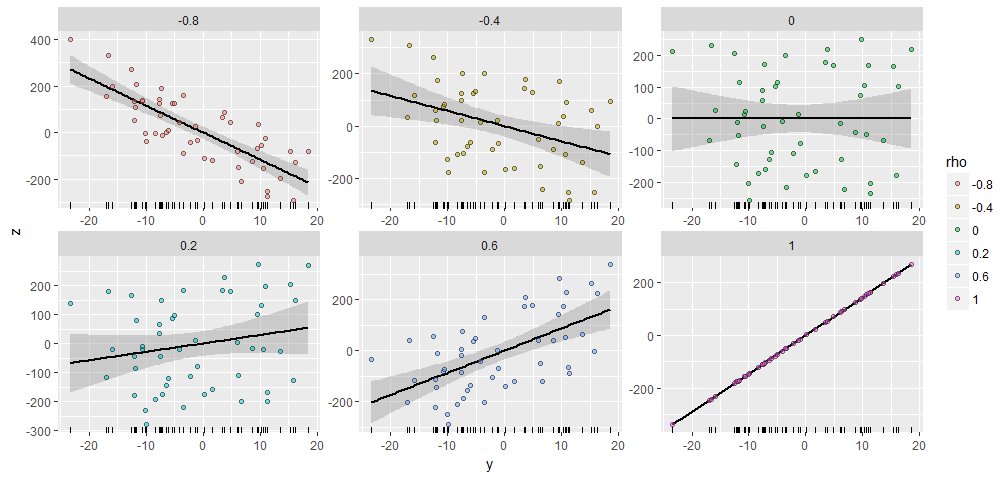
劇情之間有明顯的相似之處,不是:-)。
如果您想嘗試,這裡是產生這些數據和圖形的代碼。 (我並不在意自由地移動和縮放結果,這很容易操作。)
y <- rnorm(50,sd = 10)
x <- 1:50#可選
rho <- seq(0,1,length.out = 6)* rep(c(-1,1),3)
X <- data.frame(z = as.vector(sapply(rho,function(rho)complement(y,rho,x))),
rho = ordered(rep(signif(rho,2),each = length(y))),
y = rep(y,length(rho)))
庫(ggplot2)
ggplot(X,aes(y,z,group = rho))+
geom_smooth(method =“ lm”,color =“ Black”)+
geom_rug(sides =“ b”)+
geom_point(aes(fill = rho),alpha = 1/2,shape = 21)+
facet_wrap(〜rho,scales =“ free”)
順便說一句,此方法很容易推廣到多個 $ Y $ span>:如果在數學上可行,它將找到一個 $ X_ {Y_1,Y_2,\ ldots,Y_k; \ rho_1,\ rho_2,\ ldots,\ rho_k} $ span>已指定與整個 $ Y_i $的關聯 span>。只需使用普通最小二乘法從 $ X $ span>和形式中取出所有 $ Y_i $ span>的效果 $ Y_i $ span>和殘差的合適線性組合。 (這有助於對 $ Y $ span>進行對偶運算,這是通過計算偽逆獲得的。下面的代碼使用 $ Y $ span>即可實現。)
這是 R 中算法的草圖,其中 $ Y_i $ span>作為矩陣 y :
y <- scale(y)#使計算更簡單
e <-residuals(lm(x〜y))#取出矩陣y的列
y.dual <- with(svd(y),(n-1)* u%*%diag(ifelse(d > 0,1 / d,0))%*%t(v))
sigma2 <- c((1- rho%*%cov(y.dual)%*%rho)/ var(e))
返回(y.dual%*%rho + sqrt(sigma2)* e)
另一個線程提供了每行代碼的詳細說明。對於想嘗試的人來說,以下是更完整的實現。
互補<-函數(y,rho,x,threshold = 1e-12){
#
#處理參數。
#
if(!is.matrix(y))y <- matrix(y,ncol = 1)
d <col(y)
n <-row(y)
y <- scale(y,center = FALSE)#使計算更簡單
如果(missing(x))x <- rnorm(n)
#
#刪除y對x的影響。
#
e <-殘差(lm(x〜y))
#
#計算e的係數sigma,使
#線性組合為y的y.dual是%*%rho + sigma * e
#矢量。
#
y.dual <- with(svd(y),(n-1)* u%*%diag(ifelse(d > threshold,1 / d,0))%*%t(v))
sigma2 <- c((1- rho%*%cov(y.dual)%*%rho)/ var(e))
#
#返回此線性組合。
#
如果(sigma2 > = 0){
sigma <- sqrt(sigma2)
z <- y.dual%*%rho + sigma * e
}其他{
警告(“無法進行關聯。”)
z <- rep(0,n)
}
返回(z)
}
#
#設置問題。
#
d <- 3#給定變量的數量
n <- 50#所有向量的維數
x <- 1:n#可選:指定`x`或從任何分佈中繪製
y <- matrix(rnorm(d * n),ncol = d)#以任何方式創建`d`原始變量
rho <- c(0.5,-0.5,0)#指定相關性
#
#驗證結果。
#
z <-補碼(y,rho,x)
cbind('實際相關'= cor(y,z),
“目標相關性” = rho)
#
#顯示它們。
#
colnames(y)<- paste0(“ y。”,1:d)
colnames(z)<-“ z”
對(cbind(z,y))