這個想法是,您希望以確保網絡中良好的前後數據流的方式初始化權重。也就是說,您不希望激活過程隨著網絡的發展而持續縮小或增加。
此圖顯示了一次MNIST通過網絡後,在3種不同的初始化策略下5層ReLU多層感知器的激活情況。
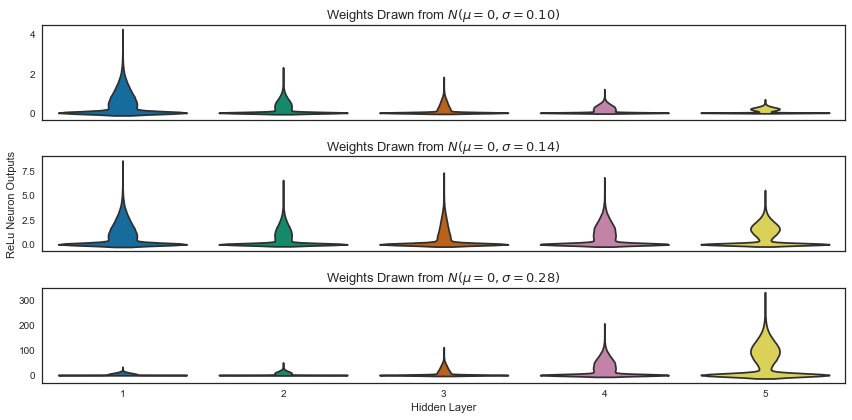
在所有三種情況下,權重均從零中心正態分佈中得出,該分佈由其標準偏差確定。您會看到,如果初始權重太小(標準偏差太小),則激活會被阻塞,而如果權重太大,則激活會爆炸。可以通過設置權重來找到中間值,即大約正確的值,以使激活和梯度更新的方差與您通過網絡時保持大致相同。
我寫了有關體重初始化的博客文章,其中有更詳細的內容,但基本思想如下。
如果$ x ^ {(i)} $表示第$ i $層的激活,則$ n_i $表示該層的大小,而$ w ^ {(i)} $表示將它們連接到第二層的權重。 $(i + 1)$-st層,那麼可以證明對於激活函數$ f $和$ f'(s)\大約1 $,我們有
$$
\ text {Var}(x ^ {(i + 1)})= n_i \ text {Var}(x ^ {(i)})\ text {Var}(w ^ {{i}})
$$
為了獲得$ \ text {Var}(x ^ {(i + 1)})= \ text {Var}(x ^ {(i + 1}})$,我們必須施加條件
$$
\ text {Var}(w ^ {(i)})= \ frac {1} {n_i} \,。
$$
如果我們用$ \ Delta_j ^ {{i)} $表示$ \ frac {\ partial L} {\ partial x_j ^ {{i}}} $,則在向後傳遞時,我們同樣希望
$$
\ text {Var}(\ Delta ^ {(i)})= n_ {i + 1} \ text {Var}(\ Delta ^ {{i + 1)})\ text {Var}(w ^ {(i )})\,.。
$$
除非$ n_i = n_ {i + 1} $,否則我們必須在這兩個條件之間折衷,並且合理的選擇是諧波均值
$$
\ text {Var}(w ^ {(i)})= \ frac {2} {n_i + n_ {i + 1}} \,。
$$
如果我們從正態分佈$ N(0,\ sigma)$中採樣權重,則可以使用$ \ sigma = \ sqrt {\ frac {2} {n_i + n_ {i + 1}}} $滿足此條件。
對於統一分佈$ U(-a,a)$,我們應該採用$ a = \ sqrt {\ frac {6} {n_i + n_ {i + 1}}}} $,因為$ \ text {Var} \ left(U(-a,a)\ right)= a ^ 2/3 $。
因此,我們到達了Glorot初始化。例如,這是Keras中密集和2D卷積層的默認初始化策略。
Glorot初始化對於微不足道的激活和$ \ tanh $激活非常有效,但對於$ \ text {ReLU} $則效果不佳。
幸運的是,由於$ f(s)= \ text {ReLU}(s)$只是將負輸入歸零,因此可以大致消除一半的方差,並且可以通過將上面的條件之一乘以2來輕鬆修改:
$$
\ text {Var}(w ^ {(i)})= \ frac {2} {n_i} \。
$$