我今天遇到了一個有趣的極端案例。
如果我們查看的樣本數量很少,則Spearman和Pearson之間的差異可能會很大。
在以下情況下,這兩種方法都報告了完全相反的相關性。
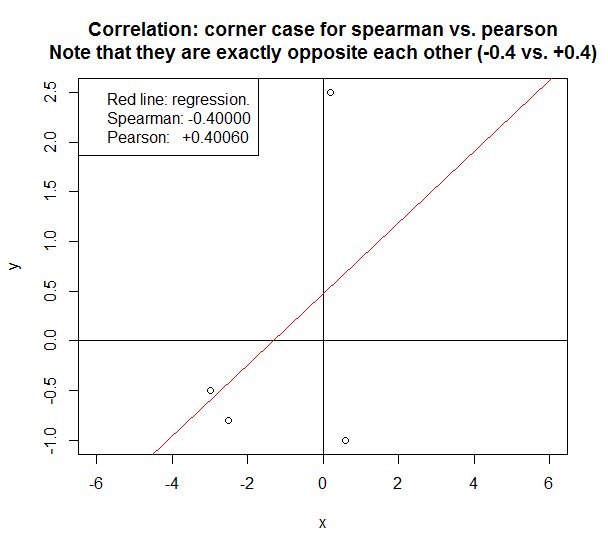
一些快速的經驗法則來決定Spearman與Pearson的關係:
- 皮爾遜(Pearsons)的假設是恆定方差和線性(或與之近似的線性假設),如果不滿足這些假設,則值得Spearmans嘗試。
- 上面的示例是僅在有少量(<5)數據點時才會彈出的特殊情況。如果有100個以上的數據點,並且數據是線性的或接近線性的,則Pearson將與Spearman非常相似。
- 如果您認為線性回歸是分析數據的合適方法,則Pearsons的輸出將與線性回歸斜率的正負號和大小匹配(如果變量已標準化)。
- 如果您的數據包含一些線性回歸不會拾取的非線性成分,那麼首先嘗試通過應用變換將數據整理為線性形式(可能是log e)。如果這不起作用,那麼Spearman可能是合適的。
- 我總是首先嘗試Pearson的方法,如果那不起作用,那麼我嘗試Spearman。
- 可以添加任何內容嗎?更多經驗法則還是糾正我剛剛推論的法則?我已將此問題設為社區Wiki,因此您可以這樣做。
p.s。以下是用於重現上圖的R代碼:
#腳本,該腳本顯示在某些極端情況下,所報告的spearman相關性可能與#earson相關。在這種情況下,斯皮爾曼為+0.4,皮爾遜為-0.4。y = c(+ 2.5,-0.5,-0.8,-1)x = c(+ 0.2,-3,-2.5,+ 0.6)地塊(y〜 x,xlim = c(-6,+ 6),ylim = c(-1,+ 2.5))title(“ Correlation:Spearman與Pearson的角案例\ n請注意,它們彼此相對(-0.4與。 +0.4)“)abline(v = 0)abline(h = 0)lm1 = lm(y〜x)abline(lm1,col =” red“)
spearman = cor(y,x,method =“ spearman”)pearson = cor(y,x,method =“ pearson”)legend(“ topleft”,c(“紅線:回歸。”,sprintf(“ Spearman:% .5f“,spearman),sprintf(” Pearson:+%。5f“,pearson)))